
Beyond Entities: A Modern Guide to Relation Extraction with LLMs
Relation Extraction (RE) is a critical NLP task focused on identifying and classifying semantic relationships between named entities in text. Moving beyond merely identifying entities, RE seeks to understand the connections and interactions between them, forming the bedrock of knowledge graph construction, information retrieval, and sophisticated question-answering systems. The integration of pre-trained Large Language Models (LLMs) has profoundly transformed RE, enabling more accurate and nuanced understanding of relational semantics. This guide offers an in-depth exploration of RE with modern LLMs, covering theoretical foundations, practical methodologies, and advanced considerations for researchers and practitioners.
Read More
Advanced Named Entity Recognition (NER) with Pre-trained Transformer Models
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that involves identifying and categorizing key information—or “named entities”—in text. The advent of pre-trained Large Language Models (LLMs) like BERT and GPT has revolutionized this field, offering unprecedented accuracy and flexibility. This guide provides a researcher’s perspective on the theory, practical application, and advanced considerations for implementing NER systems using modern LLMs.
Read More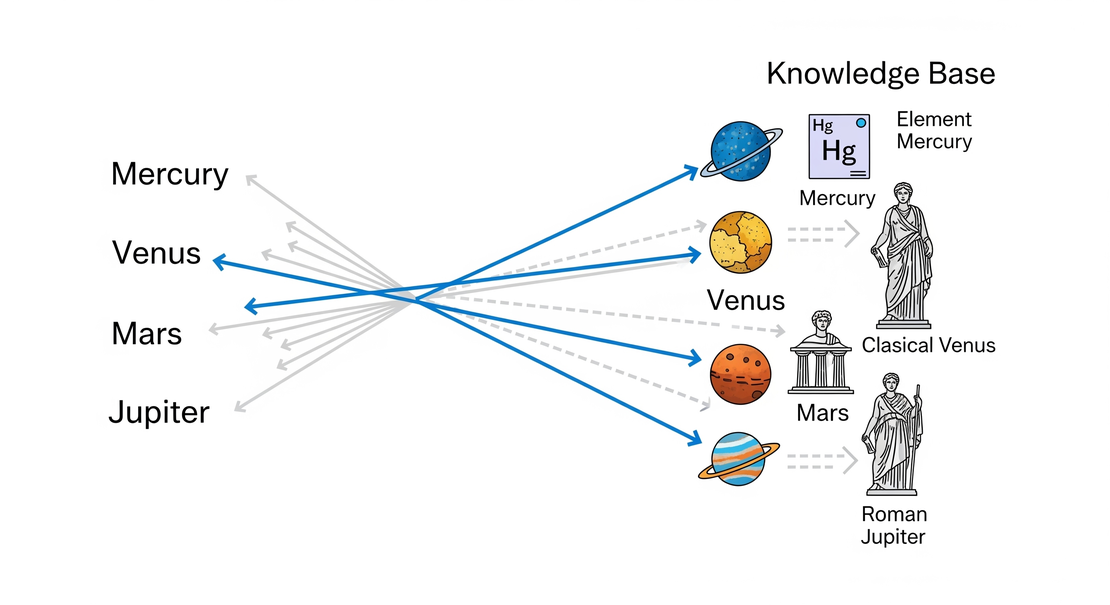
Named Entity Linking (NEL)
Named Entity Linking, also known as Named Entity Disambiguation, is an advanced Natural Language Processing (NLP) technique that extends beyond simply identifying entities in text. Its primary goal is to connect a named entity to a unique, real-world identity in a knowledge base. This is crucial for resolving ambiguity when a name, like “Paris,” could refer to multiple different things.
Read More
The State of the Art in Information Extraction: From Pipelines to Unified Paradigms
Information Extraction (IE) is a cornerstone of modern Natural Language Processing (NLP), focused on automatically extracting structured information from unstructured or semi-structured text. Its goal is to transform free-form text into a machine-readable format, such as a database or knowledge graph, enabling applications from sentiment analysis and question answering to semantic search and bioinformatics. The field has seen a dramatic evolution, moving from rule-based systems to sophisticated neural architectures, with Large Language Models (LLMs) now redefining the cutting edge.
Read More
Python-Powered PDF Text Extraction: A Practical Guide
Extracting text from PDFs is a common first step in many data pipelines, but it’s rarely a clean process. PDFs are designed for visual presentation, not data extraction, which means the raw text you get is often riddled with formatting issues like unwanted line breaks, hyphenated words, and inconsistent spacing.
Read More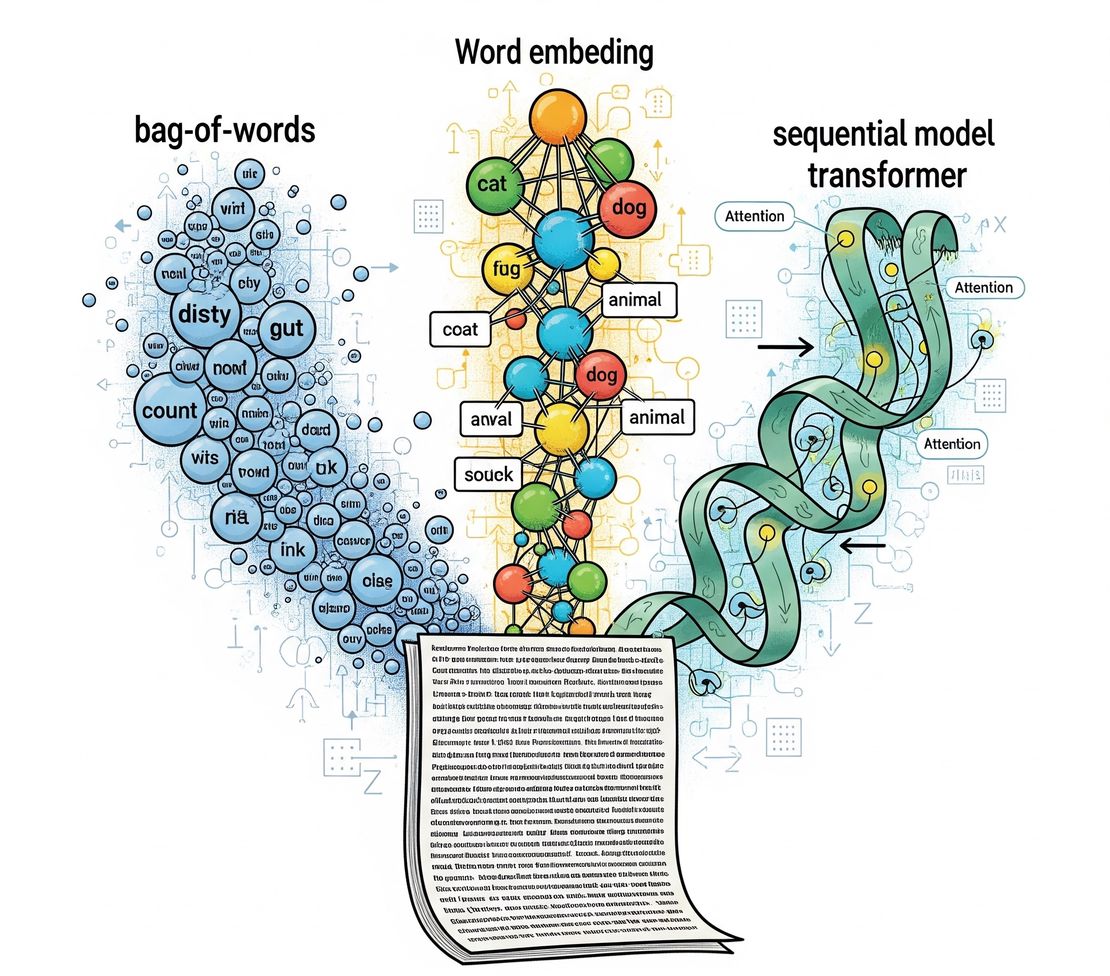
Turning Text into Numbers: The Art of Text Representation
In the world of machine learning, the quality of your features directly determines the quality of your results—a principle known as “garbage in, garbage out.” For Natural Language Processing (NLP), this means that converting raw text into a numerical format, or text representation, is one of the most critical steps in the entire pipeline.
Read More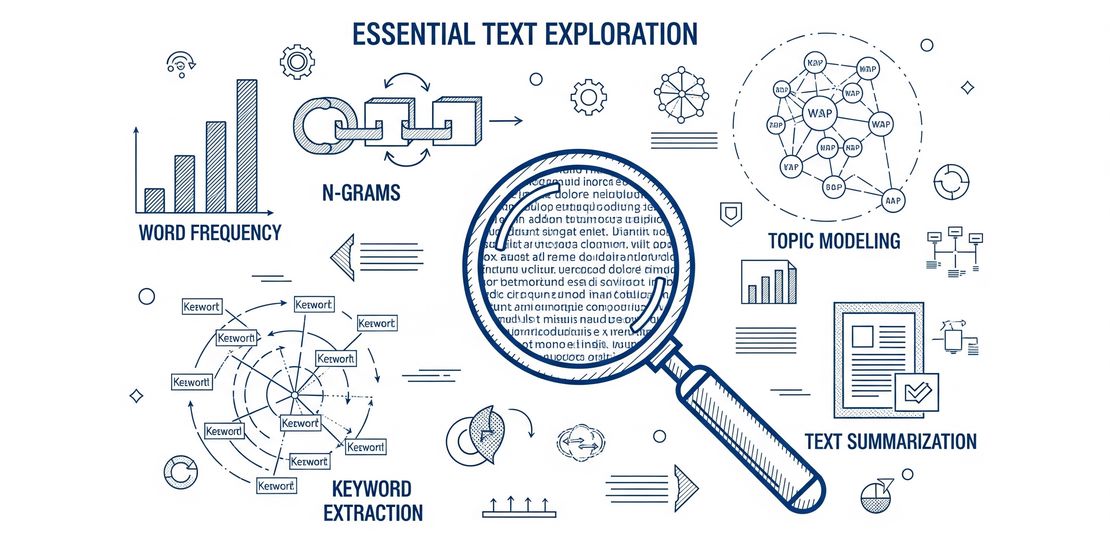
An In-Depth Guide to Essential Text Exploration Techniques
Text exploration is the indispensable first step in Natural Language Processing (NLP) and data science, where raw, unstructured text is transformed into meaningful, actionable insights. By applying these techniques, we can uncover hidden patterns, themes, and linguistic properties that are crucial for building more advanced models and making data-driven decisions. This guide details 15 of the most important text exploration techniques, complete with their applications, units of analysis, metrics, visualization strategies, and key scientific references. 💡
Read More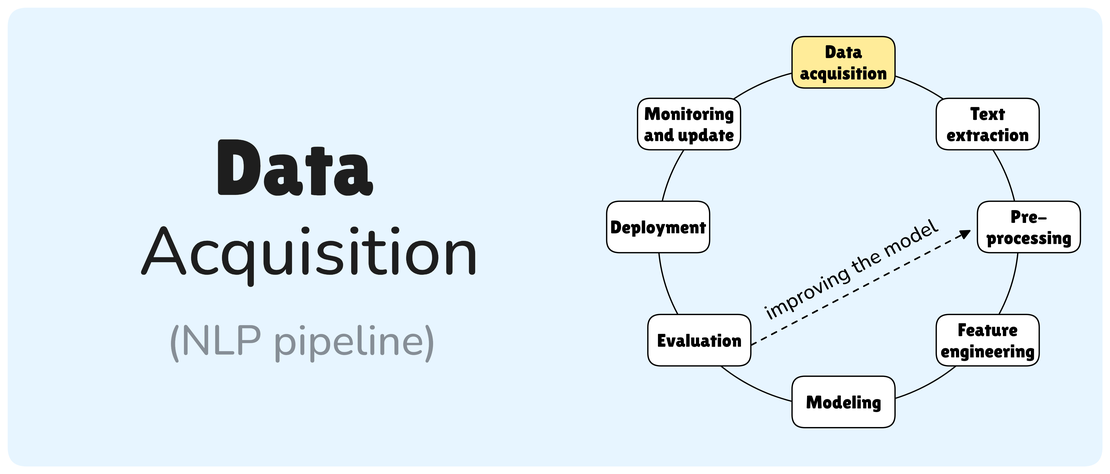
Data acquisition
Data is paramount to any Machine Learning (ML) system, frequently becoming the primary bottleneck in industrial projects. This section outlines various strategies for acquiring relevant data for Natural Language Processing (NLP) initiatives.
Read More
Evaluation in the NLP Pipeline: Measuring Model Success
Evaluation is a crucial step in the Natural Language Processing (NLP) pipeline, assessing a model’s “goodness,” primarily its performance on unseen data. Success hinges on using the right metrics and following a proper evaluation process. Metrics vary by NLP task and pipeline phase (model building, deployment, production), with machine learning (ML) metrics common in early phases and business metrics added in production to gauge business impact.
Read More
A Look at the Modern Natural Language Processing Pipeline: From Data to Intelligent Production
As an NLP learner specializing in modern techniques, I’ve outlined the essential stages of a contemporary NLP pipeline. This structured workflow transforms raw textual data into actionable insights or intelligent applications. This article summarizes these eight fundamental steps, integrating best practices and key academic references.
Read More
NLP Modeling
The development of an NLP model rarely begins with sophisticated algorithms. Instead, it’s a strategic progression, starting with what’s feasible and effective given current resources, and scaling up complexity as data accumulates and insights deepen.
Read More
Feature engineering
When working with text data in machine learning, simply pre-processing isn’t enough. We need a way to translate that cleaned text into something an algorithm can understand. This is where feature engineering, also known as feature extraction, comes in. Its core purpose is to take the unique characteristics of text and convert them into a numeric vector. Think of it as creating a mathematical representation of words and phrases. This crucial step is often referred to as “text representation” and is fundamental for any machine learning model to make sense of linguistic data.
Read More
Approaches to Natural Language Processing (NLP)
Natural Language Processing (NLP) aims to enable computers to understand, interpret, and generate human language. Over the years, several distinct approaches have evolved to tackle the complexities of natural language, each with its own strengths, weaknesses, and preferred methodologies for pre-processing.
Read More
Unlocking Language's Power: Recommended Books for Modern Natural Language Processing
Natural Language Processing (NLP) has seen a dramatic evolution in the past decade, shifting from rule-based systems and traditional machine learning to deep learning, transformers, and large language models. Staying up to date with modern practices, research, and applications requires high-quality learning resources. Below is a curated list of recommended books that cover modern NLP topics, from foundations to cutting-edge research.
Read More
Sentence Splitting in NLP: Techniques and Examples
Sentence Splitting, also known as sentence segmentation, is the process of dividing a text into its constituent sentences. It’s a fundamental task in Natural Language Processing (NLP), typically performed as a first step in various downstream tasks like machine translation, information extraction, sentiment analysis, and text summarization.
Read More
Open Source LLMs: A Comparative Analysis (2025)
Large Language Models (LLMs) have revolutionized how we interact with AI, enabling capabilities such as natural language generation, reasoning, summarization, translation, and more. While commercial models like OpenAI’s GPT-4 and Anthropic’s Claude dominate enterprise spaces, open-source LLMs have gained significant traction across research, education, startups, and independent development.
Read More
Deep Learning Project: Named Entity Recognition (NER) with LLaMA Embeddings
Named Entity Recognition (NER) is a key task in Natural Language Processing (NLP) where the goal is to locate and classify named entities in text into predefined categories such as person names, organizations, locations, time expressions, etc. In this project, we leverage LLaMA (Large Language Model Meta AI) for generating high-quality embeddings and train a deep learning model on top for the NER task.
Read More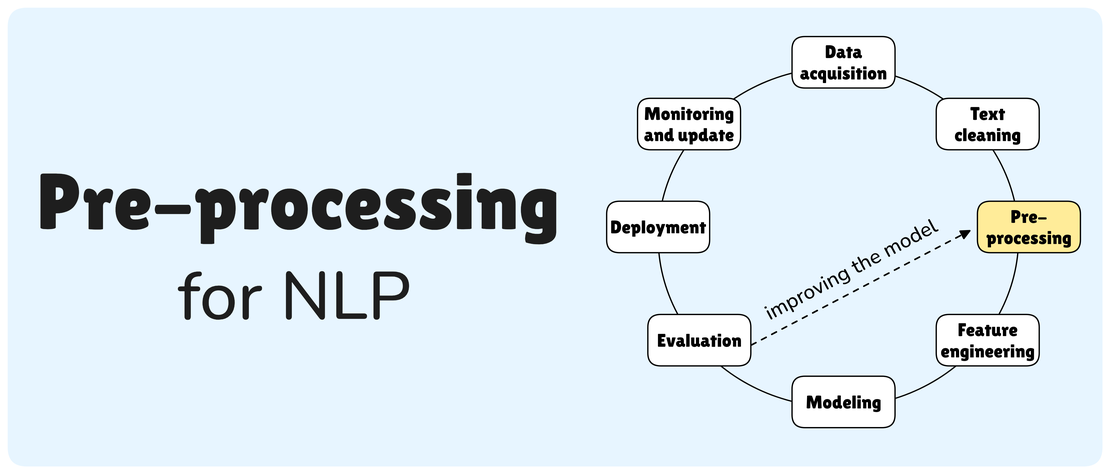
Pre-processing of unstructured text
The pre-processing of unstructured text is a critical foundational step in any Natural Language Processing (NLP) pipeline. It transforms raw, often noisy, data into a clean, normalized, and structured format suitable for computational analysis. The specific sequence and nature of these steps are highly dependent on the downstream NLP task and the chosen machine learning paradigm (rule-based, traditional machine learning, or deep learning). This article, drawing upon established scientific literature, delves into common pre-processing steps, organizing them by NLP task and the associated modeling approach, to provide a comprehensive guide for researchers and practitioners.
Read More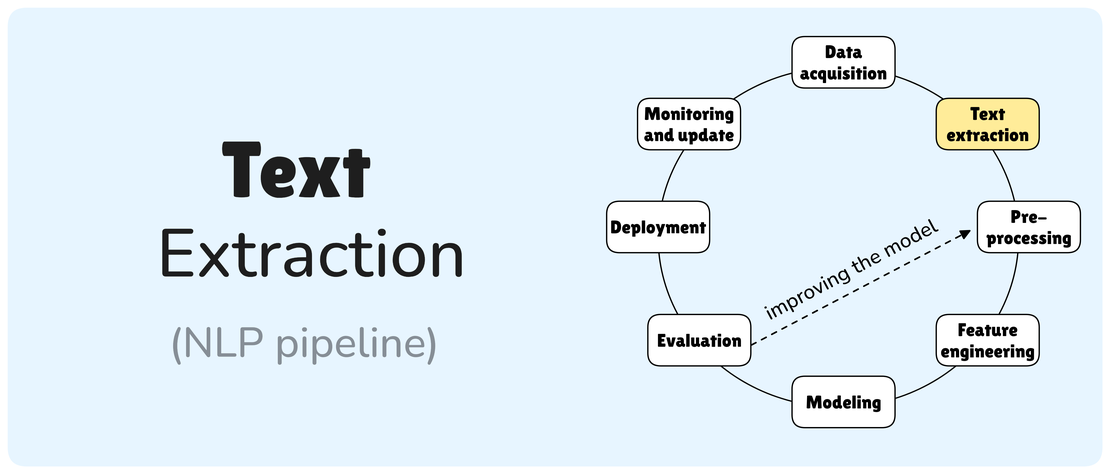
Text extraction
In the intricate world of Natural Language Processing (NLP), before any sophisticated models can analyze sentiment, extract entities, or generate text, a foundational, yet often overlooked, step must occur: text extraction and cleanup. This crucial phase is akin to preparing raw ingredients for a gourmet meal – without proper preparation, even the finest recipes will fall flat. As the provided text aptly highlights, this isn’t typically where NLP algorithms shine, but its flawless execution is paramount to the entire pipeline’s success.
Read More