Diaries...
- Home /
- Diaries...
UMAP: The Uniform Manifold Approximation and Projection Algorithm
UMAP (Uniform Manifold Approximation and Projection) is a cutting-edge, non-linear dimensionality reduction technique. Its primary purpose is to map high-dimensional data into a lower-dimensional space (typically 2D or 3D) while faithfully preserving the topological structure of the data. It is often preferred over t-SNE for its faster runtime and its ability to preserve both local and global data structure more effectively.
Read More
Beyond Entities: A Modern Guide to Relation Extraction with LLMs
Relation Extraction (RE) is a critical NLP task focused on identifying and classifying semantic relationships between named entities in text. Moving beyond merely identifying entities, RE seeks to understand the connections and interactions between them, forming the bedrock of knowledge graph construction, information retrieval, and sophisticated question-answering systems. The integration of pre-trained Large Language Models (LLMs) has profoundly transformed RE, enabling more accurate and nuanced understanding of relational semantics. This guide offers an in-depth exploration of RE with modern LLMs, covering theoretical foundations, practical methodologies, and advanced considerations for researchers and practitioners.
Read More
Advanced Named Entity Recognition (NER) with Pre-trained Transformer Models
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that involves identifying and categorizing key information—or “named entities”—in text. The advent of pre-trained Large Language Models (LLMs) like BERT and GPT has revolutionized this field, offering unprecedented accuracy and flexibility. This guide provides a researcher’s perspective on the theory, practical application, and advanced considerations for implementing NER systems using modern LLMs.
Read More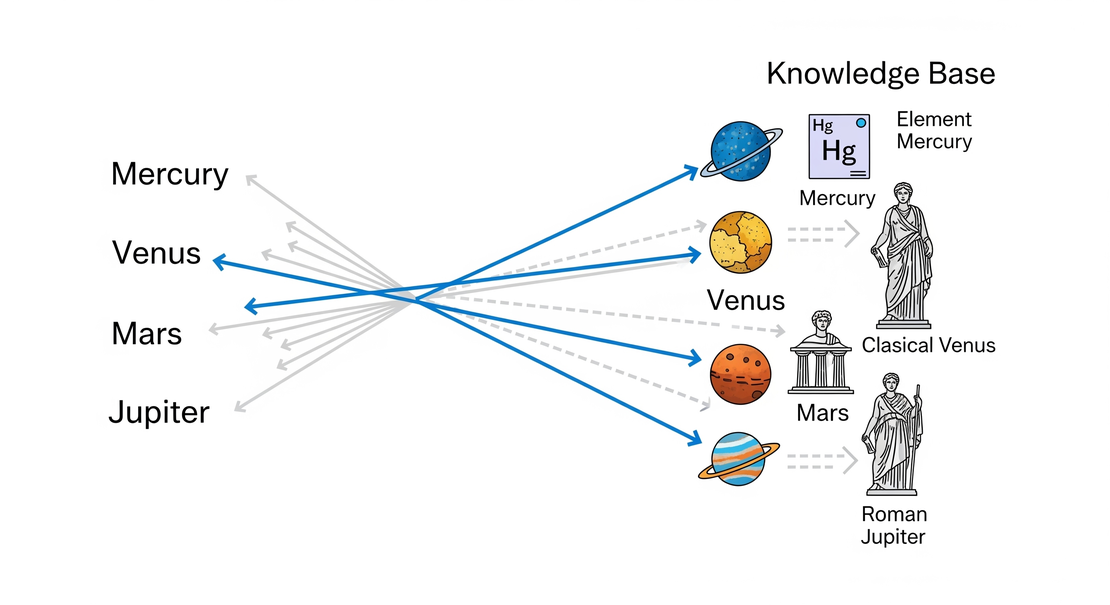
Named Entity Linking (NEL)
Named Entity Linking, also known as Named Entity Disambiguation, is an advanced Natural Language Processing (NLP) technique that extends beyond simply identifying entities in text. Its primary goal is to connect a named entity to a unique, real-world identity in a knowledge base. This is crucial for resolving ambiguity when a name, like “Paris,” could refer to multiple different things.
Read More
The State of the Art in Information Extraction: From Pipelines to Unified Paradigms
Information Extraction (IE) is a cornerstone of modern Natural Language Processing (NLP), focused on automatically extracting structured information from unstructured or semi-structured text. Its goal is to transform free-form text into a machine-readable format, such as a database or knowledge graph, enabling applications from sentiment analysis and question answering to semantic search and bioinformatics. The field has seen a dramatic evolution, moving from rule-based systems to sophisticated neural architectures, with Large Language Models (LLMs) now redefining the cutting edge.
Read More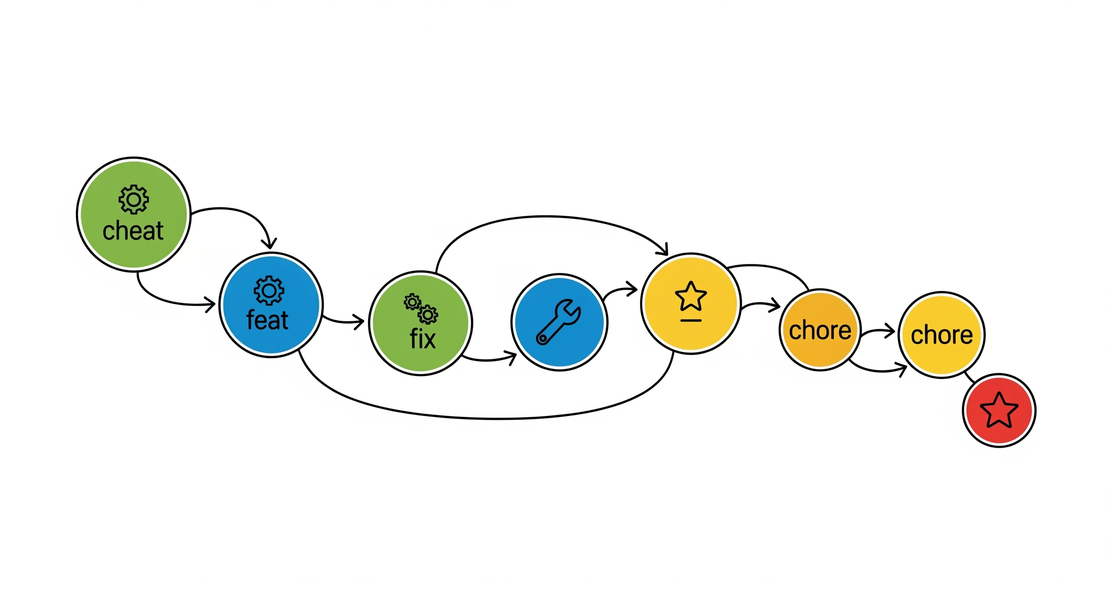
Git Conventional Commits
Git Conventional Commits provide a standardized way of writing commit messages to make them more readable and machine-parsable. The format is <type>[optional scope]: <description>. Here are some common examples and variations:
Read More
Python-Powered PDF Text Extraction: A Practical Guide
Extracting text from PDFs is a common first step in many data pipelines, but it’s rarely a clean process. PDFs are designed for visual presentation, not data extraction, which means the raw text you get is often riddled with formatting issues like unwanted line breaks, hyphenated words, and inconsistent spacing.
Read More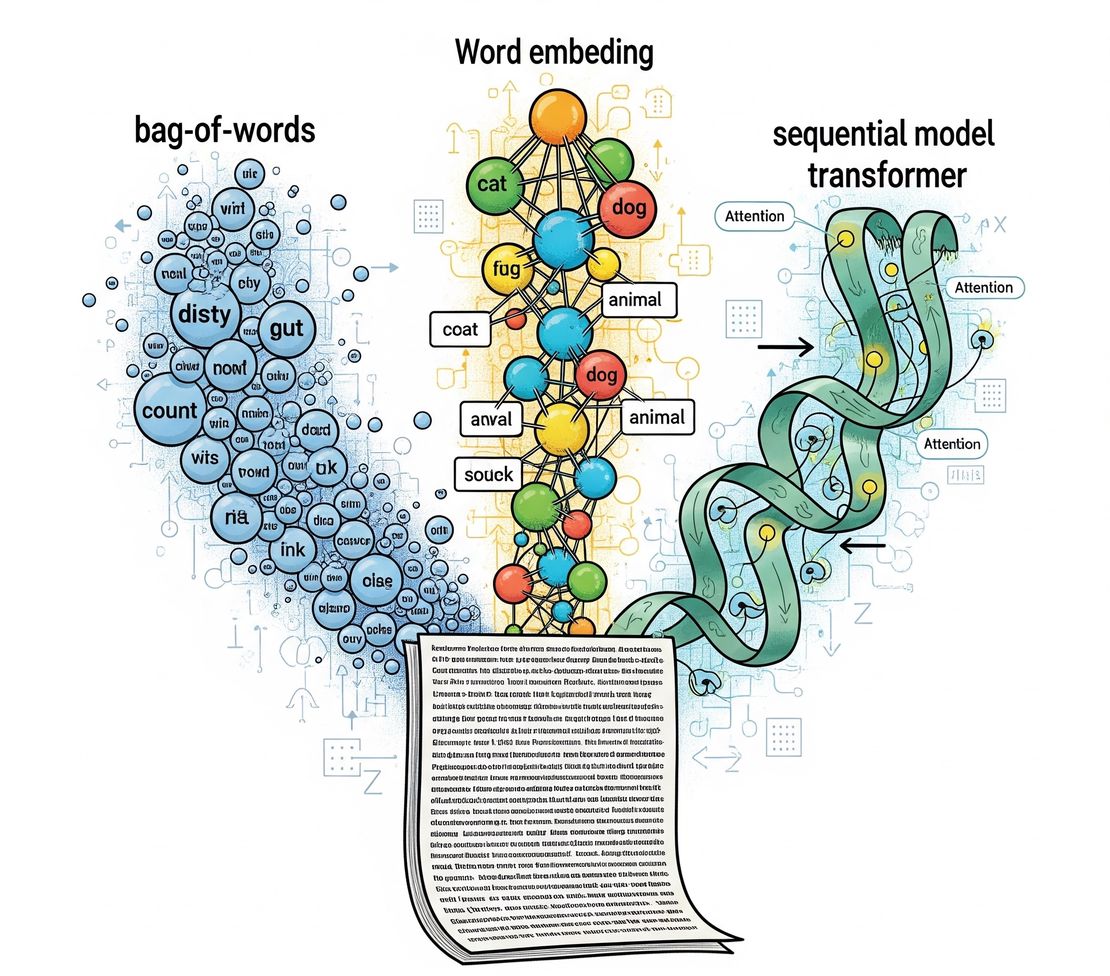
Turning Text into Numbers: The Art of Text Representation
In the world of machine learning, the quality of your features directly determines the quality of your results—a principle known as “garbage in, garbage out.” For Natural Language Processing (NLP), this means that converting raw text into a numerical format, or text representation, is one of the most critical steps in the entire pipeline.
Read More
An In-Depth Guide to Essential Text Exploration Techniques
Text exploration is the indispensable first step in Natural Language Processing (NLP) and data science, where raw, unstructured text is transformed into meaningful, actionable insights. By applying these techniques, we can uncover hidden patterns, themes, and linguistic properties that are crucial for building more advanced models and making data-driven decisions. This guide details 15 of the most important text exploration techniques, complete with their applications, units of analysis, metrics, visualization strategies, and key scientific references. 💡
Read More
Getting starter with Apache Airflow
Setting up Apache Airflow with Docker is the recommended and easiest way to get started, especially for local development. Docker isolates Airflow and its dependencies in containers, preventing conflicts with your host machine and ensuring a reproducible environment.
Read MoreCategories
Tags
- Ai-Tools
- Best-Practices
- Breadth-First-Search
- Data-Science
- Data-Structure
- Databases
- Deep-Learning
- Depth-First-Search
- Descriptive-Analysis
- Exploration
- Generative-Ai
- Git
- Graph-Traversal
- Graphs
- Hexagonal-Architecture
- Information-Extraction
- Java
- Javascript
- Jwt
- Max-Heap
- Min-Heap
- Ner
- Nlp
- Opinion
- Programming-Language
- Python
- Scrum
- Scrum-Metrics
- Sentence-Splitting
- Shortest-Path
- Software-Design
- Software-Development
- Software-Standards
- Sorting-Algorithms
- System-Design
- Team-Topologies
- Text-Extraction
- Text-Representation
- Tiobe
- Toeic
- Tools
- Troubleshooting
- Vibe-Coding
- Webflux
- Wordpress